Usenet provides a window into the Unix and BSD systems of the 1980s, and some of the hardware that they ran on. Discussions were slow. Computers were expensive. GNU Emacs was big. AT&T charged a
lot
of money. Usenet was fun.
Unix has been enormously successful over the past 55 years.
It started out as a small experiment to develop a time-sharing system (i.e., a multi-user operating system) at AT&T Bell Labs.
1
The goal was to take a few core principles to their logical conclusion.
2
The OS bundled many small tools that were easy to combine, as it was illustrated by
a famous exchange
between Donald Knuth and Douglas McIlroy in 1986. Today, Unix lives on mostly as a spiritual predecessor to Linux, Net/Free/OpenBSD, macOS,
3
and arguably, ChromeOS and Android.
Usenet tells us about the height of its early popularity.
A casual economics of Unix
Unix was not the product of a competitive market.
First of all, AT&T was a monopoly. It had the opportunity to allocate a share of its
monopoly rent
to Bell Labs, concentrating funding toward experimental projects like early Unix.
But AT&T was also a
regulated
monopoly. It was allowed to be a monopoly in telecom but prohibited from operating a non-telecom business. This prevented AT&T from commercializing Unix. Instead, it offered a source license to universities at a relatively low fee.
At the same time, universities and the US government (specifically ARPA) had a shared desire for a flexible and portable operating system. Funding from the Department of Defense allowed UC Berkeley’s
CSRG
to pay graduate students to build such an OS upon AT&T’s codebase. The resulting OS was called
Berkeley Software Distribution,
or BSD.
BSD was really good. It pushed the envelope on what Unix could be, and AT&T eventually had to adopt BSD improvements and extensions like demand paging (
mentioned later
), disk quotas, sockets, job control, or the Vi editor (
mentioned later
), because AT&T’s home-grown System III and System V were too limited without them.

The VAX-11/780, the machine on which BSD development began in earnest.
BSD got widely adopted in the 1980s by universities and research institutions. It was seen as a superior development environment, and vendors, even some big ones like DEC and Sun, based their Unix variants on it.
4
Parts of the codebase were also lifted or copied by commercial vendors. Most famous among these is the TCP/IP stack.
BSD sockets
became the de facto standard API for exposing networking capabilities to application programmers. Compatibility with it was a design goal for Microsoft’s Winsock API, which was how Windows NT could ship direct ports of some BSD userland utilities.
5
Apple (and originally, I imagine, NeXT) went even further and based MacOS X’s entire TCP/IP stack on the BSD codebase.
6
And eventually, the BSD sockets API made it into the POSIX standard.
The foundations laid with ARPA’s funding enabled new experiments to flourish. Several network protocols or their dominant implementations began life on BSD:
-
Sendmail, a mail server, first shipped with 4.1cBSD, a preview release of 4.2BSD, in 1983. It was the most popular SMTP server in the 1990s, and still prominent through the early 2000s.
-
The Berkeley Internet Name Domain (BIND) implements the DNS protocol. Its first release was part of 4.3BSD and, at least as of 2015, it still appeared to be the most popular DNS server.
-
The Network News Transfer Protocol (NNTP) made discussion groups accessible via TCP/IP, before Gopher or HTTP existed.
7
It was
proposed
by two students at UCSD and UC Berkeley in 1986, and its reference implementation
shipped with 4.3BSD
.
-
The
timed
daemon
implements the Time Synchronization Protocol, a precursor to the now-widespread Network Time Protocol (NTP). It first shipped with 4.3BSD.
Of course, not everything network-related originates with BSD. For four prominent examples, the first prototype of an Internet Relay Chat (IRC) server was built
on a Sun-3
, the first prototype of HTTP was built on a NeXT, and the first implementations of POP and IMAP were not even written on Unix but on TOPS-20 (
mentioned later
). SunOS, NeXTSTEP, and TOPS-20 were all proprietary operating systems.
But it is clear that the Berkeley flavor of Unix created an environment of freedom that fostered practical experimentation, largely detached from market forces.

Jon Hall with his New Hampshire license plate that reads “Unix,” alongside the state motto, “Live Free or Die.” He originally got the plate in 1989. (Source: Nashua Telegraph, cited by Éric Lévénez
in 2009
.)
I think that by the 2000s, it was Linux that continued the ethos of practical experimentation, although in a very different economic environment. But the 2000s are much too recent to dwell on them.
What did computing look like in the 1980s, at the height of the Unix era?
Culture
Vernacular differences
When Usenet started in 1980, it was one of the first systems
8
that allowed strangers to communicate with each other. Public bulletin boards appeared around the same time but those were more geographically localized.
Usenet was a decentralized network consisting of
sites,
and messages propagated as sites polled each other for updates. Messages were addressed to
newsgroups,
like
net.unix-wizards
,
comp.lang.c
, or
comp.bugs.2bsd
. These were similar to the later concept of mailing lists.
The early vernacular was peculiar in a few ways.
-
Articles.
It befits the idea of a newsgroup that messages were called
articles.
Early on, users occasionally even spoke of each other in the third person when sending replies,
9
in keeping with the idea of a news article addressed to the group.
-
Wizards.
In Unix circles, people who were particularly knowledgeable about the ins and outs of the system were called
wizards.
In my reading, the word is pretty much synonymous with
guru
which was also in common use.
-
Hack.
-
A quick fix or perhaps a neat solution to a problem was a
hack
(jokingly called a
haque
by a handful of people).
-
New features were
hacked up
.
People spent their time
hacking away
,
they
hacked their merry way through
source code, or were simply
hacking
.
Today’s phrase of
hacking on
a project didn’t exist yet.
-
Someone knowledgeable who tinkered with a system was often called a hacker, as in
Unix hacker
or
Interlisp hacker
,
but not for any disrespect for the law. This is the same sense in which Linux developers are still called
kernel hackers
.
-
Online.
This word originally meant something like “at the computer terminal,” not “via a network connection” like today.
10
-
The original usage is also evident in the enduring description of digital user manuals as
on-line manual pages
(
4.3BSD-Reno
, 1990;
Slackware 3.1
, 1995;
MINIX 3.3.0
, 2014;
macOS 26.0
, 2025) and
online help files
(
Windows 3.0
, 1990).
-
Using
online
to mean “via a network connection” would have been too ambiguous. In the 1980s, there was no single computer network that everyone would connect to. Instead, there were people who connected to specific Usenet sites via dial-in and downloaded software and followed discussions that way, and others who also had access to ARPANET or NSFNET and could use FTP and, by the late 1980s, NNTP.
-
The shift in meaning took until the 1990s, when the internet became available to the wider public.
-
Upward compatibility.
When comparing two versions of the same software, people preferred to speak of
upward
(i.e.,
forward
) rather than
backward
compatibility. Although sometimes they may have done so by mistake.
-
Flaming.
People regularly spoke of
flaming
each other or a piece of software like MS-DOS.
Flame wars
are still talked about today, but
flame
as a verb has gone extinct.
-
Trolling.
This word did not exist, even though trolls most assuredly did.
Flame wars took days or weeks to unfold
Flame wars were more like smolder wars. Discussions, even heated ones, typically developed over days if not weeks. This was because each article in a reply chain could take a day or longer to propagate to readers.
Usenet was a decentralized network of sites, a little like today’s Fediverse. During the early years, each site had to periodically download the latest articles from other sites, typically via dial-up. This sometimes meant polling
hourly
,
three times a day
,
twice a day
, or
daily
/
nightly
. But there were sites that had even more latency. When Australia got connected to Usenet in 1983, the Sydney site had the articles
delivered by airmail
on a weekly schedule.
As a consequence, quick throw-away quips were a little more rare. Longer messages with better-developed arguments were a little more commonplace.
Business
Old computers were sold for a long time, despite Moore’s law
Moore’s law was already in effect in the 1970s when 32-bit computers became available. Then through the 1980s, memory, storage, and computing capacity all vastly increased. This was not a negligible development.
For one thing, the PDP-11, a series of 16-bit minicomputers introduced in 1970, had a logical address space limited to 64 KB of memory. The physical address space could be expanded to 18 bits (256 KB) or 22 bits (4 MB) via virtual addressing, but accessing the additional memory regions was cumbersome because it required switching out the memory mapping table.
Yet the PDP-11 remained an important revenue source for DEC throughout the 1980s. As
Edward F. Beadel Jr.
of SUNY Oswego wrote in 1989:
Last year about 1/3 of DEC’s bucks came from PDP-11 and related sales and services. There are still many many users out there.
The architecture’s enduring popularity was mirrored by the Berkeley source releases.
2.11BSD
, the last of the 2BSD branch which existed to backport 32-bit BSD features like a TCP/IP stack to the PDP-11, came out in 1991.
This may sound like a surprising defiance of Moore’s law. But what kept the PDP-11 alive despite its limitations was that computers were still
very
expensive.
When personal computers first appeared in the 1970s, they were anything but affordable. For example, the Altair 8800, the machine for which Microsoft wrote its first product, an implementation of BASIC, cost the equivalent of $4,000 in today’s terms. The original Apple II was even more expensive, equivalent to almost $7,000. And both of these were 8-bit computers.
Historically significant computers and what they would cost today
|
Model
|
Year
|
Description
|
Price (US)
|
In
2025 dollars
|
|
PDP-7
|
1965
|
18-bit minicomputer
|
$72,000
|
$736,435
|
|
PDP-10/10
|
1967
|
36-bit mainframe
|
$110,000
11
|
$1,062,711
|
|
PDP-11/20
|
1970
|
16-bit minicomputer
|
$10,800
|
$89,647
|
|
Altair 8800
|
1974
|
8-bit home computer
|
$621 (assembled)
|
$4,059
|
|
Apple II
|
1977
|
8-bit home computer
|
$1,298
|
$6,902
|
|
VAX-11/780
|
1977
|
32-bit superminicomputer
|
$120,000
12
|
$638,078
|
|
Commodore 64
|
1982
|
8-bit home computer
|
$595
|
$1,987
|
|
Macintosh 128K
|
1984
|
16/32-bit home computer
|
$2,495
|
$7,740
|
|
IBM PC AT
|
1984
|
16-bit workstation
|
$3,995
|
$12,394
|
|
AT&T UNIX PC
|
1985
|
16/32-bit workstation
|
$5,095
|
$15,265
|
|
Amiga 500
|
1987
|
16/32-bit home computer
|
$699
|
$1,983
|
Enterprise computers, like the PDP-11 and its 32-bit successor, the VAX-11, were much
much
more expensive. The PDP-11/20, the machine on which Unix took off in the early 1970s, cost nearly $90,000 in 2025 dollars. The VAX-11/780, the first of the VAX-11 series, cost the equivalent of $638,000.
Software for these computers was expensive, too.
Frank R. Borger
of the now sadly defunct
Michael Reese Hospital
wrote about this problem in a letter to a magazine called
DEC Professional,
probably in 1986 or 1987. BASIC, Fortran, and Pascal compilers were much more expensive for the VAX-11 than for the PDP-11:
If I were to buy three packages for a small VAX versus a Q-bus PDP-11,
I would spend approximately $16,700 for the VAX software, $9,000 for the UNIBUS PDP-11 software, and only $3,600 for the Q-bus PDP-11 software. Prices for software maintenance are similarly cheaper.
When DEC tells me that it will upgrade me from a MICROPDP-11 to a MlCROVAX for $18,000 (Fall 1986 direct Update), it doesn’t mention the $13,000 difference in software costs.
[…]
Finally, there are many cases when a PDP-11 has sufficient capacity for a given job:
A system often can be put together for half the cost of an equivalent VAX.
That’s why PDP-11s will be around for a long time.
As a consequence, many customers preferred the older machines.
However, DEC made sure that upgrading to the VAX was as pain-free as possible. VAX machines had a hardware compatibility mode for the PDP-11. This enabled 4BSD systems to run old V6 and V7 binaries using
Arthur W. Wetzel’s emulation layer
which translated legacy system calls into modern ones.
13
Compatibility was a prudent strategy. It extended the lifespan of PDP-11 software, and gave customers an upgrade path to more modern systems while keeping their support contracts with DEC. Without a doubt, this stretched the company’s lifeline all the way into the 1990s, when it finally succumbed to the wildly more affordable x86-based PCs.
AT&T charged $2,000/site for the Korn shell
The Korn shell appeared in 1985, and by popular consensus, it was really good. But it was also really expensive, leaving many of its would-be users mere admirers.
During the first decade of Unix, the shell was by no means a pleasant experience. The default shell was the Thompson shell, which was then replaced by the Bourne shell in V7, and neither were comfortable for interactive use. For example, neither had:
-
command-line editing (like
readline
),
-
tab-completion for filenames and commands,
-
~
as a shortcut for
$HOME
and
~user
as a shortcut for the home directory of
user
,
-
command aliases,
-
shell history, or
-
job control.
Although Bill Joy’s C shell implemented some of these features in 3BSD, and support for job control was added by Jim Kulp in 4.1BSD, David Korn’s shell quickly became a coveted alternative.

David Korn, the creator of the Korn shell. (Source: David Korn,
1998 or earlier
.)
The C shell had several characteristics that left users wanting:
-
Its C-inspired syntax broke backward compatibility with the Bourne shell.
14
-
As far as I can tell, command-line editing was completely missing.
-
Filename and command name completion was completely missing. Tab-completion (actually, ESC-completion) was added in 1983 by the
tcsh
variant which was made by Ken Greer while at Carnegie Mellon.
15
-
By some reports, it was slower than the Bourne shell, but this was debated.
16
The Korn shell had none of these problems. Two of its celebrated features were command-line editing, which it supported with both Emacs and Vi keybindings, and shell history. And AT&T tried to monetize this.
Randy King
of AT&T jokingly paraphrased David Korn in March 1985 on
net.unix
:
Yes, ksh is available. No, it’s not $100,000K per cpu.
As I understand it,
it is $2K per
site
; i.e. all of your CPU’s can have it for that one-time cost.
In particular, the Korn shell was made available via the AT&T toolchest which was an online storefront.
K. Richard Magill
indicated in February 1986 that it was accessible via dial-up with the
cu
utility:
The AT&T toolchest is a bulletin board style store that sells source for a number of things that AT&T doesn’t want to support.
This includes ksh.
cu 1-201-522-6900
It will tell you all you care to know.
Of course, $2,000/site (around $6,000/site
in 2025 dollars
) was a hefty fee for a shell.
Gene Spafford
of Georgia Tech was of the view that it was too hefty:
Counterpoint:
Educational institutions pay $800 to get source licenses for Unix Sys V. Another $150 (?) will get a Berkeley distribution tape. Do you think many of us are going to pay $2000 for ksh?
No! Nor are many of us going to shell out the bucks that AT&T is charging for the new uucp stuff.
I don’t know about other places, but we can’t afford it here.
I guess many educational institutions, especially the public ones, will never find out if the Korn shell is all that great
, or if Honey DanBer uucp is the niftiest thing since sliced yogurt. Whether that will affect the future market for other AT&T goodies is beyond my ability to forsee.
In response,
Griff Smith
of AT&T Bell Labs called Georgia Tech a “shoestring operation” for not being able to afford the Korn shell:
I suppose the “software for the people” contingent will rise in righteous indignation, but…
Assuming that the current academic price for System V is still $800, we are still giving it away. If your school can’t afford normal commercial software prices for at least some key utilities, it must be a shoestring operation.
When I was at the University of Pittsburgh, it was “business as usual” to shell out about $5000/year for a software maintenance contract; we had to pay $10000 for the “virtual memory” upgrade for our TOPS-10 operating systems. Any useful software product usually cost us at least $1000, and some were in the $5000 to $10000 range. A large product such as DISSPLA/TEL-A-GRAF had a special educational rate of “only” $20000; the commercial rate was at least $80000.
Smith did mention that the Korn shell had also gained support for job control which would have made it more attractive to BSD users. Previously, only the C shell supported job control.
The Korn shell is a good product!
I used csh for a year; then Dave finally added BSD (i. e. real) job control and command edit mode to ksh. I switched, and haven’t looked back. Given the improvements
it can add to your computing environment,
the price is low by commercial standards.
But universities like Georgia Tech were not the only sites for which the price was not right.
Dave Ihnat
of Analyst International Corporation agreed that the Korn shell was great:
In his article, Randy King apologetically praises
Dave’s ksh
. No apology
is
needed; it’s
truly an outstanding product, and deserves whatever praise it gets. While I was on contract at Bell Labs, I used it extensively; now that my contract is over, I miss it intensely.
But I do have to take exception with the claim that it’s available.
But he considered it so unjustifiably expensive as to be unavailable. Customers couldn’t simply buy a source license for the Korn shell either. They had to also buy a source license for the whole OS which, as I understand it, cost tens of thousands of dollars:
Yes, it now can be bought; but
, according to the “AT&T Toolchest”, which I called just to make sure I’m not mistaken,
it’s $2000 per site for a source license, and
$20000 for a vendor license for object redistribution. Also, not mentioned by the Toolchest, but certified as applicable by another source, is that
you must have a System V source license to buy the source.
I’m sorry, but
I hate to break it to AT&T that most sites don’t need or want System V source licenses.
Many purchase a machine for which a vendor has done the port; they can afford the object license, but as businesses have neither need, desire, nor cash to buy their own source license–let the vendor fix bugs. Yet, at $20000, the vendors are going to have to charge a substantial sum to recoup their loss on the ksh source.
Try to explain to a bursar or comptroller why you want to spend hundreds to thousands of dollars on a new shell
–I dare you. The fact of the matter is that, whether we like it or not, it’ll be darn hard to justify significant cash expenditure for a tool
which will replace a tool which is currently doing the job, be it ‘sh’ or ‘csh’.
The same applies for the honey-danber uucp package (which, I was surprised to note, is
not
offered on the Toolchest menu). Apparently, $2000/object license (could someone verify–is that per
machine
, or
organization
? In any case, it’s extreme). Again, try to justify that type of cash outlay to an organization which has a tool that works already. Yes, I have to nurse it, watch it, and beat on it–but I’m already doing that, and we’re getting our mail and uucp traffic, sooner or later.
Ihnat pointed out that AT&T’s pricing strategy was undermining its goal of selling their supermicrocomputers to small businesses and individuals:
All of the preceeding totally ignores the fact that
the number of Venix- and Xenix-based small Unix(Tm) systems, owned by both individuals and businesses, is huge, and that
AT&T is agressively marketing the 3B2. Obviously, the average individual cannot afford a source license, or a $2000 object license
, or…
Finally, I question the propriety of overcharging in the extreme for the practice of, effectively, offering corrected versions of products which are
already
provided with the existing software, but are so bug-ridden as to be apocryphal.
No…I don’t think that ksh
(or, for that matter, honey-danber uucp)
is really available to Unix users yet.
As I said before, I applaud the efforts of Dave, Pete, Dan, and Brian; “they done good, real good”. And I can understand that it’s difficult for AT&T to figure out immediately what is the best marketing strategy, after so many years as a regulated monopoly. But, in the end,
I’m the one with a Unix machine at work, and one at home, and can’t justify the cash outlay for the tools at work, and can’t afford it at home
; and that’s the bottom line. If it’s not affordable, it’s not available.
[…]
This pricing strategy is part of why we have bash (1989), pdksh (
1989?
), zsh (1990), OpenBSD ksh (1995?), and mksh (
2002?
or
2006?
), among other shells that also cloned or took deep inspiration from the original Korn shell. Eventually, AT&T’s ksh was also open sourced, in 2000.
Software vendors were in dire need of a Unix standard
The multitude of Unix variants was truly bewildering. The situation was so bad that it posed a coordination problem for application developers.
For example, at least four different variants existed for the Intel 80286 processor as of 1985. Microsoft’s Xenix was one of those four, so naturally, Bill Gates had an opinion on this. He said that binary compatibility across the 80286 Unix variants was
a prerequisite for commercial success
.
This claim was at least a little bit controversial. Unix wizards were used to software distributed as source code that they then needed to port and compile for their own systems. It was considered normal to have to iron out bugs and add desired functionality by modifying the source. From this perspective, what mattered was source compatibility. If 90 percent of all code compiled, and the rest could be easily ported, that was good enough.
But
Larry Campbell
, an application developer, explained that binary compatibility was the only way to the mass market:
A software vendor can write a program for the
[…]
IBM PC architecture
, and can be assured that the executable binary will run on over TWO MILLION MACHINES.
That’s two million potential customers, folks.
Now, sure, software vendors
could
just ship sources
in shar archives… on 69 different types of media… and let the customers compile it… and maybe it would compile everywhere… and maybe nobody would rip off the source code and resell it…
But let’s get serious. End users
neither want nor need source code, nor compilers, nor shar archives, nor any of that crap. They
want to buy a little black biscuit with bits on it that just plugs into their little 16-bit toaster and does their application
, right out of the box, no compilation or customization or messing around required.
[…]
You need to have a single
(or at least a dominant)
binary format
and media standard
because dealers and distributors cannot afford to stock 69 different versions of each product.
[…] There’s no good reason, for instance, that Xenix, Venix, and PC/IX couldn’t use the
same
register conventions and
same
a.out (x.out) formats and the
same
system call numbers.
[…]
He concluded with a pithy summary:
Yes, I prefer Unix. But I also prefer large quantities of money to smaller ones.
That’s why I develop software for the IBM PC.
The problem was not limited to the 80286. The Motorola 68000 (or m68k) was maybe even worse.
Michael Tilson
of the HCR Corporation emphasized that building, testing, and distributing separate binaries for each Unix variant for the m68k was prohibitively costly:
Distribution in source code form is not the answer for commercial software. One could imagine software vendors who sell source code only, but this is not practical for most vendors. Software is already easy to steal, and unlimited distribution of source code is almost a license to steal (it certainly requires a much larger policing effort.) Most software vendors make their living selling binary copies, with only the occasional source code sale. If the software could be protected, most would be happy to sell source only, but it can’t and they don’t. There are technical problems as well –
you want to sell a program that you
know
will run. If you haven’t actually compiled it on the target machine, you don’t know what compiler bugs you might hit, etc.
(Note: Please no flames about the moral wrongness of binary code. In our economic and legal system, binary code will continue to be the norm, even if some think it wrong.)
Therefore vendors sell binary code. As a software vendor, we at HCR find the multiplicity of machines to be a real pain.
We can live with
the fact that you must make
a 68000 version and a VAX version of a program, but it is very costly to make 10 different 68000 versions.
A binary standard would eliminate needless duplication effort.
As software companies go, we are fairly big (60 people using almost $1,000,000 worth of computer equipment) but we can’t afford to deal with all of these formats.
Therefore we are targeting our new products to a few “winner” machines.
Perhaps Tilson exaggerated when he wrote “10 different 68000 versions,” but not by much. The m68k was a popular architecture for workstations and home computers. HP, Sun, Microsoft, AT&T, Silicon Graphics, NeXT, and Apple, as well as smaller companies like
Datamedia Corp.
and
Pixel Computer Inc.
, all made Unices or Unix-likes that ran on CPUs from this series.
17
On this scene, HCR may have been something of a Red Hat or SuSE for Unix, albeit closed source. It was described by Byte magazine in 1994 as
the second firm
to commercially support Unix. The computer equipment cost that Tilson cited translates to $50,000/person in 2025 dollars, which is not insubstantial. And HCR had the life arc of a successful startup: it was founded in 1976 and got acquired by SCO in 1990, to serve as their Canadian branch. Unfortunately, it then went defunct in 1996.
Hardware
Virtual memory was the hot new thing
The VAX-11/780 (1977), and the less powerful but smaller 11/750 (1980), were Unix workhorses through at least the mid-to-late-1980s.
The new VAX machines came with a memory management unit (MMU) that allowed kernels to implement virtual memory using demand paging. Demand paging is now standard, but it wasn’t in the 1970s. What it does is it lets running applications hold onto memory regions (pages) that are not actually in physical memory unless they are accessed (demanded).

The VAX-11/750 supermini. (Photo credit: José Luis Echeveste, 1988. License: CC-BY-SA.)
Before the 780, no Unix system implemented demand paging. They had to instead resort to a memory management strategy called
swapping
. As I understand it, these early kernels kept the entire memory image of each active process in physical memory. When physical memory ran out for a scheduled process, they moved the entire image of one or more other processes from memory to storage, thus freeing up memory for the image of the scheduled process. In the words of
Joseph L. Wood
of AT&T in 1983:
Steve Dyer’s article makes the same semantic mistake that I have seen in many articles recently. The specific statement made is that BTL UNIX doesn’t have ‘virtual’ memory for its VAX version. Of course it has virtual memory; what it doesn’t have and what all the submitters mean is that BTL UNIX doesn’t implement a paging virtual mamory system. BTL UNIX implements virtual memory meaning that the address bit pattern generated in an instruction or by some arithmetic operation in a register for example is translated by a memory management unit before a main store reference is made. On the other hand,
when BTL [Bell Telephone Laboratories] UNIX needs some more main store, it selects a process to be deleted and ships the whole image to a swap device. When Berkeley UNIX needs some more main store it looks for a page to delete. This is more efficient than the BTL way.
The other alternative which is becoming more attractive for many sites is to just buy enough memory. That runs faster than either.
There were two problems with swapping. First, by all accounts, it was slow. If you were the unlucky owner of an interactive process, say, a text editor, that got swapped out while running, this ordeal made you unhappy. Sure, this was a problem on underpowered PCs like the
AT&T 6300 Plus
which lacked an MMU capable of demand paging. But it was even an issue on supercomputers where physical memory was contended by many concurrent users (
mentioned later
, tangentially).
The other problem with swapping was that the kernel could not run any process whose memory image was larger than the machine’s physical memory.
Guy Harris
mentioned integrated circuit design as an application where this constraint may have been binding:
Unfortunately, I believe there are applications where “buy enough memory” is either impractical or impossible.
I believe a lot of the applications that 4.2BSD is being used for simply require more address space than you can provide purely with the physical memory attachable to a VAX;
the VLSI design and image processing software that has been mentioned as prime applications for VAXes and 4.2BSD may fall under this heading.
A paging kernel can, for example, support the
mmap
system call which lets applications read and write files as if they were fully loaded into memory, even if those files are larger than the available physical memory. An overview of this and other benefits of paging was offered by
Randolph Fritz
of Western Union Telegraph in 1983.
AT&T Unix, however, used swapping even on VAX machines until System V Release 2 in 1984. They ported V7 to the 780, the result of which was
UNIX/32V
, but this port did not implement demand paging. So one of the goals of 3BSD in 1979 was to do just that by taking advantage of the 780’s MMU.
Even with virtual memory, superminicomputers were slow
With its 32-bit port, BSD became a VAX-first Unix. Partly due to its better memory management, it proved useful for universities, research labs, and many enterprise users. Then, since ARPA also purchased several VAX-11/750s, 4.1BSD in 1981 added support for these machines, too.
The VAX-11/780 and the 750 were called
superminicomputers
or
superminis.
But even with demand paging, they were not what we would recognize as fast. On some level this is obvious: the 780 came with a 5 MHz (1 MIPS) CPU and it supported between
2 to 8 MB
of memory.
18
But the comparison is interesting because we still use very similar tools to what people ran on BSD.
Think about the code you write and run today. How much longer would it take to run it on a VAX in 1985?
For statistical analysis, one of the popular languages in use is R. R’s proprietary precursor was called S, and it ran on 32-bit Unix.
Jim Leinweber
of UW Madison shared performance measurements on their 780 running BSD:
|
S snippet
|
11/780 running 4.2BSD
|
ThinkPad X1 Carbon running Linux
19
|
Multiplier
|
write(1:10000, "/tmp/junk")
|
25 s
|
14.04 ms
|
1,781
|
m <- matrix(read("/tmp/junk"), 100, 100)
|
20 s
|
7.72 ms
20
|
2,591
|
for (i in 1:20) for (j in 1:20) m[i,j] <- sin(j/10)
|
timed out
|
3.00 ms
|
N/A
|
Here is what each row means:
-
Creating a vector of 10,000 integers and writing it to a file took 25 seconds.
-
Reading the vector back into memory, turning it into a square matrix, and assigning the result to a variable took 20 seconds.
-
Initializing a 20-by-20 matrix element-by-element took too long to complete.
And 4.2BSD was the
fast
Unix (
mentioned later
).
It would be easy to blame S’s slowness on the 780’s CPU or memory. CPU clock rates were lower, after all. Memory access was slower, too. If I understand the 780’s hardware handbook correctly, it had a memory bandwidth of
about 13 MB/s
.
But none of the benchmarked S snippets were CPU-bound, nor were they memory-intensive. The 780 came with at least 2 MB of physical memory, and 10,000 unboxed
int
s fit in less than 40 KB. Even if S boxed every
int
, it is unlikely that the vector used more than 80 KB.
Rather, the snippets were bottlenecked by I/O. On these systems, writing data to temporary files was common practice because memory was an extremely scarce resource. And boy, did S take the practice to heart. In Jim Leinweber’s words:
[…]
I’m not an expert on the bowels of S, but
a cursory glance at $M/lang3.yr shows that
each occurence of `<-’
invokes $F/assign, which in turn calls $L/getds, $P/pcopy, and $L/putds. Thus one problem with the nested for loop is that assignment is very expensive in S;
apparently
each assignment
copies a dataset from one file to another!
Doing O(n^2) complete file rewrites to initialize a matrix is
bound
to be slow
So I/O was not only slow, it was also more frequently necessary to resort to it because memory pressure forced the kernel to swap and applications to save their work to storage.
12-core machines already existed in 1985, kind of
Interactive workloads were very ill-suited for single-CPU multi-user systems like the VAX-11/750. Nowadays, we carry multi-core entertainment systems in our pockets. Yet in the 1980s, typically even machines the size of a large fridge had only one single-core CPU.
But there were exceptions. Notably, Sequent Computer Systems’s
Balance
line of machines
were multi-CPU systems with 10 MHz processors from National Semiconductors. The Balance 8000 could be configured for up to 12 CPUs, with six dual-CPU boards. These machines shipped with a modified version of 4.2BSD, so they could run any workload that a stock 4.2BSD could in its native habitat, on an 11/750.
Keith Packard
of
Tektronix Inc.
wrote in 1985 on
net.unix-wizards
:
Sites like this might want to look into systems like the sequent balance 8000
or other multi-cpu systems. We have had a sequent box for about 3 months and I, for one, would never consider buying a vax again in a multi-user environment.
It’s got 6 32016’s
and a mess of iop’s
and runs 4.2 unix. For single job execution it performs about like an 11/750. For 6 job execution it performs about like 6 11/750’s.
Even the i/o bandwidth doesn’t seem to slow it down a bit, the notoriously cpu bound 4.2 file system has a party with 6 cpu’s serving it!
And, the best part, it costs less than a
single
11/780! Also, it is housed in a rather small box (1m deep, 2m wide and <1m high).
I use it for software development - edit, compile, link… and have been working with ~1M of code. I was on an 11/780 with about 30 other software designers, load averages of 20-40 not uncommon. The sequent box has been wonderful.
Despite the Sequent Balance’s good showing against the 11/750, I don’t imagine that these models came close to the VAX’s popularity. I couldn’t find a single photo of a Balance machine anywhere, either in promotional materials or deployed. There are several photos of what it looked like inside the box though.

A 360mm-by-310mm dual CPU board from a Sequent Balance, showing two NS32332 processors alongside their cache memory. Customers could add multiple such boards to a Sequent machine if their workload required. (Source:
cpu-ns32k.net
.)
What happened to Sequent after this? The company kept up with the growth of the 80386 and started building machines around Intel CPUs. Eventually, they got acquired by IBM in 1999. Although both Sequent and IBM said that Sequent’s products would continue to be sold, IBM discontinued them by 2002.
Laptops were expensive and
heavy
By the late 1980s and the early 1990s, laptops started becoming affordable. Among manufacturers of such portable computers, Toshiba was well-regarded.
Even 16-bit laptops were useful quality-of-life improvements. One such computer was the Toshiba T1000SE, which
used
the Intel 80C86.
John Osler
of Dalhousie University used his as a thin client to their VAX in 1991:
I use my T1000SE extensively as a terminal emulator for our VAX mainframe
by running the EM4105 software package from Diversified Computer Servives.
It has
no trouble
communicating at 19200 bps and has a subset of Kermit available for file transfer operations
. Also included are a number of screen, printer
and
plotter graphics drivers, among these, the T3100 driver
uses the full 640 by 400 resolution of the
T1000SE
screen
to emulate a Tektronics 4010, 4105 or VT640 graphics terminal. All this to say that the the T1000SE can be used very effectively as a terminal emulator.
But neither affordable nor portable meant then what we think today that it means.
The T1000SE weighed only 2.6 kg (5.8 lbs; see
brochure
) and sold for
about $1,200
in 1990 (equivalent to $2,960 in 2025). That doesn’t sound so bad compared to high-end laptops today but we need to remember that this was a 16-bit computer.
Gaston Groisman
of U Calgary also had good things to say about the T1000 but said that the laptops used by his wife’s professors rather difficult to lug around:
wife has a T1000 and she caries it to school almost every day (walking).
She deos mostly word processing and some e-mail and loves it.
At the same time some of her profesors have heavier machines (Zenith 181?) and they keep them on their desks all the time, even though they drive!!
We also took the laptop in out trip back home to Argentina and it was a great way to get my daily fix of programing and playing. Finally, given the prices I have seen advertized the T100 seems the best combination for writing, traveling, etc.
The Zenith 181, released in 1986, had a 16-bit Intel 80C88 processor and 640 KB of memory. It weighed 5.4 kg (11.8 lbs; see
brochure
).
For a higher-end example, the Toshiba T3100SX, released in 1989, was more desirable. It had a 386 CPU and a 40 MB hard drive. It was sold with 1 MB of RAM but that could be expanded to 13 MB. With two batteries, you could get 2 to 5 hours of battery life out of it.
All in all, this laptop should have been a wizard’s trusty travel companion. It being a 386-based machine made it particularly attractive because of the prospect of running Unix on it. No more messing around with the 80C86 or the 80286!

A laptop with
demand paging
and the weight of seven ThinkPad X1 Carbons.
But the T3100SX cost upwards of $5,000 (about $13,000 in 2025 dollars). And it weighed 6.8 kg (15 lbs; see
a contemporary brochure
and
a later fact sheet
).
Toshiba also made other 386-based laptops.
John R. Levine
of Segue Software asked about the T5200 in 1990:
I am looking for a Unix system that I can take with me on trips, so as not to lose a moment’s hacking time merely because I happen to be on top of some mountain with spectacular views or something.
Here are what I think I need:
[…]
Running on batteries is unimportant, when I’m on a plane I sleep.
The Toshiba T5200 appears to qualify nicely
on every point except perhaps the last. (It has one long and one short internal slot, enough for an internal Telebit modem and an Ethernet card.)
Has anyone actually run 386/ix or some other Unix on one? Is there some other machine I should be considering?
A lunchbox machine like the Compaq Portable 386 would be a possibility, though the Compaq is pretty expensive and its expansion memory is unbelievably expensive.
Thanks, as always, in advance
The T5200 weighed 8.4 kg (18.5 lbs; see
brochure
). Contemporary brochures don’t mention a price, but Keith Comer, a product manager at Toshiba America, said
in a 1989 TV program
that prices started at $9,500 ($24,697 in 2025). It is hard to imagine that there was a market large enough for the these laptops for Toshiba to break even.
So Unix-ready laptops were heavy luxury items that most people seemed to buy on organizational budgets. But laptops were already taken on airplanes. The fear that they emit radio waves that interfere with navigation systems had mostly been put to rest, and many people took advantage of this.
Joseph S. Brindley
of California Polytechnique wrote in 1990:
This was an early fear expressed by ignorant airlines when laptops first came out but it is not grounded in fact as
most, if not all, laptops have a FCC class b rating. I have used mine many times. No crashes yet! :-)
The exact etiquette of bringing electronics aboard a plane may still have been in flux.
Anthony J. Stieber
of UW Milwaukee wrote:
At one time there was a lot of hysteria about problems with RFI from laptops on aircraft, but that was several years ago.
Before I flew it was suggested that laptop users talk to the pilot about using a laptop on board.
[…]
Basicly they were pretty unconcerned about it. It was like they were thinking “Why are you asking me? I don’t care.”
[…]
I would still ask the pilot about using any kind of electronics that I bring on board the plane.
Going through airport security was interesting. I asked to have my machine hand checked rather than go through the x-ray machine. They wanted me to turn the machine on, it’s a Toshiba T1000 which boot from a ROM disk, the guard remarked on how quickly the machine came up. That was a bit scary, especially when they didn’t ask to look in the large zippered pocket or the largish disk cases. The thing that most excited them were the cables and my shaver in my backpack which they saw as it went through the x-ray machine. They did ask to look in there, but lost interest after a quick look.
I’m sure security will vary alot depending on which airport it is, where you’re going, and whether there have been threats or problems recently.
Software
Unix had to be tinkered with, but it could at least be tinkered with
Unix was not the only operating system in use on enterprise computers. Even ignoring third-party OSes, DEC itself shipped several alternative systems for its machines. Its PDP-11 minicomputers ran RSX-11 and RSTS/E into the 1990s. The PDP-10 mainframe, a 36-bit architecture, ran TOPS-20. The VAX superminis ran VMS.
Among these, Usenet article authors spoke particularly fondly of TOPS-20. During the time when command and file name completion on 32-bit Unix was only implemented by tcsh and AT&T’s $2,000 ksh (
mentioned earlier
), and when Unix’s documentation was generally lacking, TOPS-20 already had both of these areas covered.
Yet nowadays, it is VMS that is the best remembered (and in fact still actively maintained as “OpenVMS”). It was backwards compatible with RSX-11, and generally regarded as a stable, low-fuss OS.
In 1984,
Jon Forest
of UCSB liked VMS more than Unix because the latter was too much work to keep running:
I run VMS. One of the reasons I prefer VMS to Unix is because
VMS is much easier to maintain. In essence, I don’t do any maintainence because DEC does it all for me
at a fixed rate. I can plan my budget knowing exactly how much it will cost be to run VMS.
With Unix, software maintainence requires one or more gurus who spend lots of time on the phone, going to conferences, reading nets like this, and hacking.
The worst part of this is that so much effort is duplicated. For example, how much time has been spent by all the Unix users in the world to find and fix the bugs that are now being described. I bet that each bug has been found and worked on by more than one person. This is wasted time.
The counterpoint was that Unix’s source license enabled sites to fix bugs without waiting for the vendor. As
Henry Spencer
of the University of Toronto put it:
Having DEC do all your software maintenance
has the obvious advantage that you don’t have to do the work. It
has the obvious disadvantage that you can’t do the work even if you want to and need to.
Your degree of satisfaction is clearly a function of how responsive DEC is, and you have no input in deciding that.
Since you run VMS, you have no viable alternative if you come to dislike their service; they know this.
GNU/Linux and a truly free BSD were still almost a decade away, but Unix already gave at least its academic users more freedom than any other OS. This relative freedom defined Unix’s culture.
Mark Crispin
of
Stanford University
thought that Unix wasn’t the only OS that needed “wizards”:
This sort of issue comes up whenever people get the impression that there are any absolutes.
Just about any system can benefit from having an on-site wizard, even if the operating system is manufacturer-supported (e.g. VMS, TOPS-20, VM/370).
While the cost of ownership of a wizard is non-trivial (yes, they do “spend lots of time on the phone, going to conferences, reading nets like this, and hacking”), consider the alternative. You are either stuck with the product as it comes from the manufacturer or you find yourself forced to rent a wizard – that is, you must hire a consultant.
Now I have nothing against consultants!
I’m a full-time rental wizard (tr: independent consultant) and I find the business quite lucrative.
I hope that attitudes such as Jon Forrest’s continue – customers with that attitude comprise most of my business.
Rather than the wizard issue, he saw two major problems with Unix. The first was tribalism, his description of which rings familiar:
The “people problem” with Unix is
not the wizards, but rather
the groupies. I define a “Unix groupie” as any individual who (1) considers Unix in its present state to be software perfection, (2) refuses to believe that other operating systems have features too, (3) makes noises of disgust whenever some other operating system is mentioned, (4) makes noises of disgust whenever some programming language other than C is mentioned.
It’s reminiscent of the APL\360 groupies of 15 years ago.
The second problem was the fractured landscape created by Unix’s many variants (
mentioned earlier
):
Unix does have a software maturity problem. I for one would love to see a standard Unix.
It unnerves me when I must relearn “how to do X” just because I’m using somebody else’s Unix system.
Many of these incompatibilities seem to be completely gratuitous.
Also,
Unix lacks some very basic facilities
which are only now starting to appear: process-to-process memory mapping (for both read and write), process-to-file memory mapping, file interlocks, long file names, user-friendly command interfaces (sh, csh, ksh, etc. are many things, but user-friendly is not one of them), etc.
I wish that these things would all appear in all places in the same way, but I fear that in just about every minor version of Unix it’ll be completely different.
He did think that VMS had its place, but he was not as impressed by it as some others on Usenet seemed to be:
Unix is clearly not for the fainthearted. If
you really don’t care all that much what the operating system does for you – e.g.
all you want is a FORTRAN engine
–
then Unix may not be your answer. You can use a “throwaway” operating system such as VMS.
If you actually start USING some special feature of your operating system, you may start caring about what happens when you have to change computer vendors.
Finally,
I cannot let the comment about “Unix being better than any other operating system (except VMS)” go by unchallenged. I can’t see how anybody can possibly make such grand claims about VMS. It’s
the manufacturer-supplied operating system for a superminicomputer which is now (with the 8600) selling at (high) mainframe prices. It’s an upgrade from an earlier minicomputer operating system from that manufacturer, but
still some years(!) away from achieving the level of functionality of other operating systems from that manufacturer’s other product lines!
It’s still a dinosaur.
Those “other operating systems” that Mark Crispin was talking about? Mostly TOPS-20, which he
still ran at home
in the 2000s.
BSD was generally seen as faster and more innovative than System V
System V had a reputation for being better documented and making fewer breaking changes than BSD. However, many innovations and improvements to System V originate from BSD. I’ve
already mentioned
some examples earlier. But BSD also added smaller quality of life improvements, like filenames that could be
longer than 14 characters
and a C compiler that allows identifiers
longer than seven or eight characters
(where the System V compiler imposed limits of seven for globals, eight for locals).
BSD was generally considered faster than System V. This was also the case for Berkeley’s “fast file system” (FFS), although there were some conflicting reports in this case.
John Bass
mentioned in 1985 that this was probably because ARPA and other major BSD users were running atypical workloads that involved large files:
People forget that 4.1 and 4.2 were paid for and tuned for AI Vision and CAD/CAM projects
sponsored by ARPA and various compainies. For the job mix that 4.x systems are tuned for it is the ONLY way to do those jobs on a UNIX machine with any cost effectiveness.
Many tradeoffs that go into 4.x systems
are directly counter the best ways to tune UNIX systems for development environments … but they
were the only way to make things work for the target applications.
The converse is also true to a large extent … V7/SIII/S5 kernels don’t handle large applications well or at all
— try running a 6mb application on an older bell system with swapping …. it takes many seconds for a single swap in/out.
[…]
As for the 4.2 “fast filesystem” … it was again tuned to make large file transaction run at an acceptable rate
…. try to load/process a 4mb vision or cad/cam file at 30-50 1k block transactions per second – it will run SLOW compared to a production system with contigous files. A number of tradeoffs were made to help large file I/O and improve the transaction rates on very loaded systems (LIKE ucb ernie … the slowest UNIX system I have ever used …. even my 11/23 running on floppies was faster).
As Guy Harris pointed out in a different discussion, BSD was also well-suited for integrated circuit design which represented a similar workload (
mentioned earlier
). Overall, Berkeley’s early support for demand paging went hand in hand with performance tuning in other subsystems, like FFS.
The original
/bin/sh
supported goto
The Bourne shell, introduced in 1979 in V7, is what we think of today as the Unix shell. But Unix’s original
/bin/sh
, the Thompson shell, was an uncanny creature.
This old shell had already fallen into obscurity by 1986, when
Kenneth Almquist
gave a taste of it on
net.unix-wizards
. (You might recognize Almquist as the original author of
/bin/sh
on NetBSD and Debian.)
He provided the following sketch of an early shell script:
/bin/if $1x = x /bin/goto usage
[commands to do actual work go here]
/bin/exit
: usage
/bin/echo "Usage: command filename"
/bin/exit 1
This snippet is nothing if not strange. How could
/bin/goto
, a child process, alter the order in which the shell script was executed?
Almquist explained that this was possible because the Thompson shell read the script from standard input (i.e., file descriptor 0) and allowed
/bin/goto
to change the shell’s position in the input:
[…]
/bin/goto performs a goto, just like its name implies.
The implementation of /bin/goto depended upon the fact that the shell read shell scripts on file descriptor 0 using unbuffered reads. The /bin/goto program would seek to the beginning of the script and read forward until it came to the specified label
, which appeared on a line beginning with a “:”. The “:” command does nothing; it was actually a shell builtin even at this early date.
[…]
Criticism of the Bourne shell is not new. Almquist himself already complained in 1988 that shell scripts are hard to get right because of their complicated semantics (
mentioned later
). Nevertheless, it was a clear improvement over the status quo:
[…]
Needless to say, all this broke with the Borne shell, which didn’t read shell scripts on the standard input.
One reason that the Borne shell was accepted as a replacement for the old shell is that in a shell script of any size the gotos became unreadable.
The big change in converting to the Borne shell consisted of replacing all the gotos with structured flow of control statements, which was obviously a worthwhile enterprise even if the Borne shell had not required it.
GNU Emacs was big
GNU Emacs already had its enthusiasts when it was first released in 1985. Just like today, extensibility was what most people mentioned back then as its most appealing feature. For example,
David M. Siegel
of MIT praised it in March 1985:
I cannot image why people would not want GNU Emacs.
It is by far the best Emacs I have ever used; far better than one you could buy.
It is amazingly easy to add features to it. For example, a few of us added a netnews reading mode to it
(very similar to vnews)
in one weekend.
The mail reading program is very similar to Babyl, and probably one of the best you can get for a Unix system. All in all, it is hard to beat.
But Emacs wasn’t just extensible, it was also a good enough terminal multiplexer. In 1990, when X11 was already around, X11 was desirable but
Perry Smith
of IBM found Emacs featureful enough to forego that:
[…] If we totally disrequard price, is there a laptop which runs Unix in a true multi-process environment? I’d like to have BSD Unix (or mach). […] I think 5 mips would be plenty though. I’d also like to have an expandable disk system where I could have a limited amount of disk in battery mode and a huge amount of disk when I finally got back home. I don’t expect all the disk to be housed in the laptop. Unix by itself is big plus I like to use emacs and TeX and some other huge packages so I need quite a bit of disk space. But I don’t need this when I’m sitting on a plane (for example).
Oh, while I’m blowing smoke rings –
I’d like eventually to be able to run some sort of X windows or similar package. This is actually not a big deal since emacs gives me all the environment I need. The advantage of emacs as an X client though are sorta neat
and I’d love to be able to have those capabilities as well.
Has the technology even approached such a beast? If so, who makes it and how much is it going to set me back? (I’m willing to go pretty high if I really like what I see.)
The problem was that GNU Emacs was
big.
Even in 1985. The source code was 2.2 MB uncompressed, and people weren’t really sure how to distribute all that without
filling up the disks
of Usenet sites.
Jeff Hull
of
TRW Inc.
suggested sharing the source over 18 or so weeks:
How about
stripping all extraneous material (e.g., the .o files) out &
posting it in 64K pieces, say 2 per week?
You might be thinking, why didn’t they compress the source code before sharing? The reason is that, at the time, only plain-text files could be shared via Usenet and email. Base64 encoding, which we use to serialize binary files,
wasn’t proposed until 1987
.
But GNU Emacs as a running process was big, too.
Brad Miller
of
Computer Consoles Inc.
worried that it wouldn’t even fit in system memory:
I have at least one complaint. It is HUGE.
Sorry, but when my OS won’t run it because it only supports 1 meg processes, I start to wonder.
As a result, various micro-Emacsen were popular for a long time. Freemacs was one alternative, but it had other limitations, as
Chris Brewster
of Cray Research reported in 1991:
I have had the same question. I wanted a program that would be compatible with the GNU Emacs that I use at work.
I especially wanted some of GNU’s features such as multi-step UNDO and extensibility. The most GNU-like program is Freemacs, but the 64K file size limit is a real problem for me, and it doesn’t have UNDO.
Going by people’s comments about other PC Emacs’s, I think that they would also fail to meet my needs. But I have heard that the Brief editor is fully configurable and extensible,
and
has multi-step UNDO and a lot of power. If it’s configurable, maybe it could be given an Emacs-like interface. I’d be interested in others’ experience with Brief, and opinions about how well it could be made to emulate Emacs commands.
Other popular contenders were MicroEMACS, MicroGnuEmacs, and JOVE.
21
These not only limited themselves to an essential feature set, they also chose
a different data structure
(a linked list of lines) for storing edited files in memory than GNU Emacs did (a
gap buffer
).
Piercarlo Grandi
of UCW Aberystwyth compared the performance of the latter two editors with GNU Emacs in January 1990:
The lesson
I derive
from these timings is that creating the linked list of lines
, and especially copying the file to a temporary as well,
slow down file reading time, but then further operations become very much faster. Note also that both MicrGnu and Jove are somewhat carelessly coded, with lots of quadratic algorithms.
Ah, another note: in my favourite editor buffer organization,
I would use the gap method, for
intra
line editing, as it avoids a lot of these quadratic situations
(e.g. repeated inserts or deletes).
Grandi also noted that the gap buffer could be made much more efficient by taking into account the size of the machine’s cache line:
Note that on cached machines this can be further improved; the hardware string move instructions typically hard coded in memcpy(3) and friends are often very suboptimal.
On a cached machine you really want to split your transfer in three parts (if long enough!), a head and a tail that are copied byte-by-byte, and a body that is copied one cache line at a time, and is cache line aligned in the
destination
.
Especially on machines with write thru caches, writing cache line aligned cache line sized chunks is
vastly
faster, as it avoids the cache fetching a line only to partially update it and hold ups at the memory interface.
I remember that on a VAX-11/780
with an 8 byte SBI write buffer,
writing aligned 8 byte transfers was
tremendously
effective.
Supercomputers couldn’t run Vi and Emacs either
So smaller computer struggled with GNU Emacs. But supercomputers did, too. In fact, text editors in general were a problem on multi-user systems.
Both Vi and Emacs
were reported to cause performance degradation on supercomputers like Cray X-MPs and Y-MPs.
Rafael Sanabria
of NASA wrote in 1990 on
gnu.emacs
:
We are having a heated discussion
here at the lab
because our computer administrators
are afraid that vi or emacs will degrade the performance of these supercomputers. The
say that vi issues an interrupt for every keystroke and that will degrade performance.
Along the same lines,
Booker C. Bense
of the San Diego Supercomputer Center explained on
comp.unix.large
why running Vi and Emacs on the Crays was not a good idea:
An editing process
requires an entry that
remains in the process table for a significant amount of time
using a significant portion of that time in system calls.
[…]
So while I have only made a few changes,
I have been in the editor for many minutes. All this time
the editor is patiently waiting for keypresses, unless of course my process got swapped out.
Note: in this example I have not used any more cpu time than in the test examples above, however I have caused the scheduler that much more grief. While I do not pretend to know the inner workings of the UNICOS scheduler,
I know trying to edit files at around 3pm here is an exercise in patience.
This led to workarounds like remote editing. GNU Emacs users had
ange-ftp
which copied modifications via FTP. Vi users had
rvi
, of which there were actually
two variants
. One variant generated
ed
commands while the other used FTP.
Security
By modern standards, Unix wasn’t secure
In 1983, the University of Toronto had a VAX-11/780 running 4.1BSD with a modified kernel because of
”the somewhat hostile environment created by the undergraduates”
. Surprising, maybe, but definitely amusing. Unfortunately, the modifications they made were not detailed.
There was a general sense on Usenet that Unix was full of security holes. As a logical consequence, people believed that it was dangerous to divulge details about vulnerabilities because the typical deployment was not about to be updated. So, unfortunately, the historical record is light on the specifics.
Some early problems with Unix that are well-known:
-
In V7,
chroot
could be broken out of by running
cd /..
because
..
was a pointer in the file system to the parent directory, not a symbol that was resolved based on the root directory. This was fixed in 4.1BSD and System III, according to
Guy Harris
in 1983.
-
Encrypted passwords in
/etc/passwd
could be cracked by bruteforce until SunOS or System V (I’m not sure which) introduced
shadow passwords
in the mid-to-late-1980s.
-
Setuid root
binaries were pervasive.
-
For example,
ps
originally ran with setuid root to read
physical memory via
/dev/mem
, and later kernel memory via
/dev/kmem
, for information on running processes. The situation was slightly improved later by adding a
kmem
group, making
/dev/kmem
readable only by the group, and running
ps
with setgid instead. But, of course, letting an attacker read arbitrary kernel memory was still not ideal.
-
Actually, for a while, even shell scripts could run with setuid bits. This was criticized, among others, by
Kenneth Almquist
in 1988:
[…] People tend to use the shell for quick hacks which work right in most cases. But being a little bit insecure is like being a little bit pregnant. The fix is to put as much thought into writing a setuid shell procedure as you would into writing a setuid C program.
In fact, writing a setuid shell procedure is
more
difficult that writing a setuid C program because the semantics of C are simpler.
[…]
-
Authentication over network connections was typically unencrypted. Encryption was either not available or not used.
John Carr
of MIT reported that they addressed this in 1987 by switching to Kerberos.
Code quality had room for improvement. For example, dereferenced null pointers were reportedly a common issue. On VAX machines, this was a legal operation, and it seems that programs often assumed address zero to contain an empty null-terminated string, i.e., a byte equal to zero.
Dave B. Johnson
of Rice University was working on a Unix emulator for VMS and had to grapple with this problem. He wrote in 1983:
Many programs under Unix at least unknowingly use the fact that using a zero pointer as a “char *” will give you a null string.
Although these are many times bugs which nobody has yet found,
we have found
in bringing up Phoenix under VMS
that a large number of programs will break if there is not a null string at 0.
The way this works on a VAX is that the entry point for crt0 contains a register save mask which specifies that no registers be saved. Since crt0 gets loaded at address 0, this results in a zero word at address zero, and thus, a null string at 0. In answer to your question:
What if I do “int *a = 0, *b = 0; *b = 10; i = *a;”? What is the value of i? Does this mean that assigning indirect through a nil pointer is deadly to the rest of your nil pointer derefs?
the result would be a Bus Error, since location zero is part of the text, rather than the data, and is thus write protected (except, of course, under the OMAGIC format where the result in “i” would be 10). I have not found any programs that try to write at address 0, but there certainly are those that rely on reading there.
The reason that programs got away with this was that BSD implicitly placed a null byte at address zero.
22
In the 4.1BSD source tree, this was done in
src/libc/csu/crt0.s
, in the startup routine that called the
main
function in compiled executables.
Of course, this hack was frowned upon, and efforts were made to weed out null pointer dereferences in Unix, including in tools like
awk
(as reported by
Guy Harris
in 1985) and
sed
(as noted by
David Elliott
of MIPS in 1988).
Home brewed systems programming solutions also seem to have been common. Toronto’s modified kernel is one example. As another example, on the topic of bruteforcing
/etc/passwd
,
Steve Dyer
wrote in 1982:
At Harvard we replaced /etc/passwd with a hashed-on-logname, fixed record organization, with “private” information (such as encrypted passwords, student ID nos., etc.) kept in a parallel, publically-unreadable file.
And, yes, it’s very easy to encapsulate these changes by rewriting the handful of get**ent routines. Standard Bell or Berkeley programs run without reprogramming. For those few programs which might migrate to our system in binary form, we regenerated an /etc/passwd file (with a phoney password field) every morning.
This wasn’t only for security but also for performance. On larger systems, memory limitations and slow storage I/O made plain-text lookups very slow:
It wasn’t a realistic possibility
for us
to use
the
/etc/passwd
organization,
because we had over 2500 unique lognames
on each of our 11/70’s.
[…]
Such modifications existed at other sites, too.
Peter Collinson
of the University of Kent reported a similar scheme in 1983.
23
User-friendly
/bin/su
alternatives were already a popular utility genre
The original Unix security model centered on users, groups, and read/write/execute file permissions.
I’ve mentioned setuid/setgid bits in the previous section. These file permissions allow users to run certain binaries as if they were a different user or members of a specific group. Probably until the early 1990s, Unix made heavy use of this mechanism. For example, did you know that
/bin/df
was setuid root on 4.1BSD? Or
/bin/mv
,
/bin/mail
, and
/usr/bin/at
? Or
/usr/games/fortune
?
Setuid/setgid was frowned upon, but the alternatives were unwieldy. Every time a user needed to execute a command as root, they had to either log in as root or, and this was the recommended method, use the
su
utility to get a temporary root shell.
The
su
utility was
already present
in First Edition Unix in 1971. However, using
su
was clunky because every time it was invoked, the user had to enter the root password and wait for it to be validated against
/etc/passwd
(or later, the shadow password file).
Aside from the inconvenience of having to type the same password again and again, this seems to have been slower than on today’s systems because of the sluggishness of storage devices.
Many people tried to address these problems by inventing alternatives to
su
. In December 1985,
Kevin Szabo
of the University of Waterloo shared a small utility called
asroot
, written for System III.
Karl Kleinpaste
followed up with an even simpler utility called
enable
that did the equivalent of calling the C library function
system()
as root. But neither
asroot
nor
enable
performed any permission checking.
Paul Summers
posted another utility called
force
which asked the user for the root password before executing the command. The root password was compiled into the executable “to save time,” I presume because of high storage I/O latencies on contemporary hardware. Apart from the hardcoded root password,
force
was similar to running
su
with the
-c
flag which
su
already supported
at the time.
In response,
Clifford Spencer
of
BBN Communications Corp.
posted an early version of
sudo
. It consisted of a single C source file and included a rudimentary version of permission checking. It allowed arbitrary command execution if the user was listed in
/usr/adm/sudo.users
.
About five days later,
Don Gworek
posted a modified version
24
that was capable of restricting user permissions to specific commands. Like modern
sudo
, it used a file called
sudoers
:
Permissions in sudoers are either “all”, a list of commands, an enviornment PATH variable, or a PATH followed by a list of commands.
Fun trivia:
sudo
was
originally developed
at SUNY Buffalo on a VAX-11/750 running 4.1BSD.
Conclusion
The Usenet archives are vast, and there are many more topics that I could not cover here despite being interesting. For example, the debates around moving Unix from static linking to shared libraries, or complaints about BSD’s subpar documentation which is surprising given the reputation of its modern descendants. I might get to those topics in the future. Or maybe you will and I can read about them?
-
Dennis Ritchie and Ken Thompson (1974)
described the design and early development of Unix. It already accumulated a good number of deployments early on:
There have been four versions of the UNIX time-sharing system. […]
Since PDP-11 UNIX became operational in February, 1971, over 600 installations have been put into service. […]
↩︎
-
Neil Brown has an article series on LWN, called
Ghosts of Unix Past
. The series describes both successes and failures of Unix’s design patterns, and areas where the core principles weren’t followed through consistently.
↩︎
-
Yes, unlike Linux and the BSDs, macOS is certified as compliant with version 3 of the
Single Unix Specification
. But does it actually borrow code from AT&T? I don’t think it does but I’m not sure.
↩︎
-
For context, it has to be mentioned that Sun was co-founded by CSRG alum and erstwhile BSD contributor Bill Joy. Later, Sun and AT&T formed a partnership to integrate BSD and AT&T’s System V, the result of which was System V Release 4, or SVR4, completed in 1988. Sun then migrated its own operating system from 4BSD to SVR4 as the new foundation. This led to the release of Solaris 2 in 1992.
↩︎
-
Copyright strings embedded in
rsh.exe
,
rcp.exe
,
ftp.exe
, and
finger.exe
suggest that these executables borrowed source code from BSD. The Internet Archive stores a copy of
a Windows NT 3.1 installer
. Download
Disc01.iso
and then run:
$ mkdir -p /tmp/nt/{disk,binaries,copyright}
$ sudo mount -o loop Disc01.iso /tmp/nt/disk
$ cd /tmp/nt
$ cp ./disk/i386/*_ ./binaries/
$ cd binaries
$ for i in *_; do msexpand $i; done
$ rm *_
$ for i in *; do strings $i | grep -i copyright > ../copyright/$i; done
$ cd ../copyright
$ grep -ri copyright .
If you’re not on Linux, replace
mount -o loop
with the equivalent method for mounting a CD image on your OS. On Debian and Ubuntu,
msexpand
is shipped by the
mscompress
package. The last command will print:
rsh.ex:@(#) Copyright (c) 1983 The Regents of the University of California.
rcp.ex:@(#) Copyright (c) 1983 The Regents of the University of California.
ftp.ex:@(#) Copyright (c) 1983 The Regents of the University of California.
finger.ex:@(#) Copyright (c) 1980 The Regents of the University of California.
↩︎
-
MacOS X’s
kernel programming guide
describes BSD as being the originator of the kernel’s networking facilities. A
2005 brochure
for MacOS X Server writes:
It begins with an open source core and BSD networking architecture—delivering the capabilities you expect of a UNIX operating system, such as fine-grained multithreading, symmetric multiprocessing, and protected memory.
[…]
Using the time-tested BSD sockets and TCP/IP stack, this advanced networking architecture ensures compatibility and integration with IP-based networks.
↩︎
-
NNTP eliminated the need for copying entire newsgroup archives to the local disk for access to specific threads on Usenet, which was a distinct improvement over the prevailing UUCP.
↩︎
-
If you’re thinking,
”didn’t email also exist in 1980?,”
you’re right. Email was invented in the 1960s, more than a decade before Usenet. In 1971, First Edition Unix
already included
the
mail
command for exchanging messages with other users on the same system. I don’t know when exactly
mail
, or 2BSD’s
Mail
, became networked. But every email had to be addressed to a specific person rather than an amorphous group of strangers like Usenet newsgroups. In this way, email remained limited to peer-to-peer communication.
↩︎
-
An example from
a 1983 debate
about what did and didn’t count as support for virtual memory:
Believing Mr. Woods’ claim about System V having virtual memory requires an implementation of “virtual reality.”
I seriously hope that Mr. Woods’ misunderstanding is not indicative of AT&T’s understanding of the issues. If it is, …
↩︎
-
For example,
Joshua Gordon
seems to have used “online” in its original sense in June 1984 on
net.micro
:
I’m running
on a “partitioned” system right now: an altos-586 running
XENIX with, yes, a 10-meg disk.
Indeed,
there is not a heck of a lot of room on here
(I have the development package); only a few man pages (mostly for stuff I got on the net, and a few pieces of local stuff); it is somewhat of a nuisance, but I can certainly understand a company partitioning the system. Even without the development package, ten megs is not much.
and I’ve stripped the thing myself even more (got rid of spell and its froofraw; chucked out useless phototypesetting utilities; that sort of thing) so
I can keep at least a few days news online at a time.
Likewise did
John Sellens
of the University of Waterloo in January 1985:
I need a copy of the DIF (Data Interchange Format) standard. We have written to the clearing house, but want it as soon as possible.
If you have it already online, I would appreciate it if you could mail me a copy.
Andy Glew
of
Gould Electronics
mentioned this in September 1987 on
comp.unix.wizards
as one of the benefits of spending money on a PC:
But seriously, on a home computer you don’t have
the hassle of having
to ask permission to do something
, or of becoming root without asking permission and then getting yelled at because you tread on somebody’s toes.
You can make your own decisions as to what is important enough to keep online, and what should be deleted, or backed of to tape or floppy.
You have floppies, which are a much more convenient storage medium than tape for reasonably sized modules (even when you have more than 400 floppies, like I do).
Even as late as in March 1988,
Ric Messier
of
Lyndon State College
reported on
comp.unix.wizards
that Unix was lacking “online help,” unlike the IBM systems he had used:
Now, you can all go to your corners and start flaming me if you like but I haven’t seen anything in UNIX yet (particularly its speed) that would convert me.
As for its documentation,
which I have seen others talk about,
it is absolutely ATROCIOUS
. And there is almost NO online help,
unlike IBM’s FULL-SCREEN online help about anything you could possibly need to know.
As of yet, I haven’t had much chance to play with anything serious in the way of scripts or command languages on Unix or VMS but I can tell you that what I have seen endears me even more to IBM’s Rexx.
In the replies,
David H. Wolfskill
differentiated between manual pages that were just “online” and those that were stored on a server:
It was about yet
another
variant implementation of UNIX from IBM; naturally it is different from all others that have been offered so far. It is called
”IBM/4.3” – a port of BSD4.3 for the Reduced Technology :-) PC.
It seems quite interesting; it seems to be based on some of the work done at CMU for Andrew (and some of that code is part of IBM/4.3).
[…]
At least IBM/4.3 – unlike the 370-based flavor(s) of UNIX that IBM offers –
can have the “man” pages online…. (Of course, with IBM/4.3, you’d probably have them on a server.)
Some articles made an explicit distinction made between “online” and “available via a network connection.” For example,
Mark Reynolds
of Adaptive Optics Associates inquired about RFCs that described SMTP in December 1985 on
net.wanted
:
I would like to get a hold of copies of
RFC 821
“Simple Mail Transfer Protocol”
RFC 822
“Standard for the Format of Arpa Internet Text Messages”
Are there online copies of this that can be accessed via USENET ( we are not an ARPA site ) ?
Similarly,
Karl Nyberg of USC’s Information Sciences Institute
wrote in February 1986 on
net.lang.ada
:
Since I have had several requests for this recently, I have checked, and found that
there is an online copy of the Reference Manual here on ISIF. The files may be found in the directory ps:<ada-lsn>
, and are listed as anxi si-rm-*.. They appear to be somewhat dated (the latest write date is February 83), and have a number of disclaimers concerning the preliminary nature of the document, etc.
For those of you on the internet, you can use Anonymous Ftp to transfer these files and review them.
For those of you not on the internet, please don’t ask to have them mailed - they’re huge! Perhaps I will work out a mechanism for making some (small) quantity of tapes if interest warrants, and I can find the time.
↩︎
-
A
1967 price list
showed the cheapest PDP-10 configuration at $110,000.
↩︎
-
The Computer History Museum
lists the price as a range
: $120,000 to $160,000. I am taking the lower bound of this range as a guesstimate for the introductory price. The VAX-11/780 was a popular model that was sold for a number of years. So it is conceivable that the introductory price was higher.
↩︎
-
As
Mark Horton
was quoted in 1985:
In the second place, what’s really happening here is that
these binaries are PDP-11 binaries (that’s what V6 and V7 ran on) which are run in VAX compatibility mode
(the VAX hardware supports such a thing)
using a program called /usr/games/lib/compat
and a front end to open the files.
↩︎
-
The first thing that
Bill Stewart mentioned about the Korn shell
in November 1984 on
net.unix-wizards
was compatibility:
It is (almost) totally upward compatible from /bin/sh (the Bourne Shell). This means that /bin/sh scripts that used to work still work, and you don’t have to relearn everything like you would if you switch to csh.
↩︎
-
Ken Greer summarized his changes
in October 1983 on
net.sources
:
The following code enhances the Berkeley C shell to do command and file name recognition and completion.
The code is limited to a new module and a hook into sh.lex.c. Also included is a manual update “newshell”.
I’ve had the file name completion code running for years. Thanx go to Mike Ellis of Fairchild A.I. Labs for adding command recogition/completion.
This version is for 4.1 BSD. If the 4.2 shell is any different and this requires any change I’ll repost.
↩︎
-
Anderson and Anderson’s 1986
The UNIX™ C Shell Field Guide
wrote (
Section 1.6, page 23
):
The C shell was originally designed on a large machine
, where system resources and memory were not at a premium.
It executes slowly in many small computer implementations.
However, as low-cost computers become more powerful and the cost of memory decreases, this will become less of an issue.
A couple years earlier, in June 1984,
Geoff Kuenning shared this opinion
on the C shell as a regular user:
Apparently some people have come to the conclusion that I think csh is the greatest thing ever. Let me say this right now:
csh *** S T I N K S *** !!!
It is
inconsistent, ugly, badly human-engineered, inconvenient,
slow to start up scripts
, buggy, and full of nasty surprises. It also happens to be the shell I use for interaction and for scripts. For interaction, the explanation is simple: aliases and history. For scripts, I learned how to write csh scripts (and it was PAINFUL) because that was the shell I knew how to use, and it never occurred to me that sh might be better for scripts even though csh is a better interactive shell.
↩︎
-
SunOS descended from 4.2BSD. HP-UX, Xenix, IRIX, and A/UX descended from System V. NeXTSTEP used a Mach kernel with code from 4.3BSD-Tahoe and 4.3BSD-Reno, preview releases of the later 4.4BSD.
↩︎
-
In the late 1970s and the early 1980s, in the years after the 780 was introduced, there was no commonly understood way of characterizing its performance.
Joel S. Emer of DEC and Douglas W. Clark of Princeton wrote
in 1999:
In particular, while the VAX-11/780
, which was introduced in 1978,
was
probably the
preeminent
timesharing machine
on university campuses
at that time,
very little was known about how it worked or
exactly
what its performance was.
(They dated the 780 to 1978 but the Computer History Wiki
traces the original announcement
to DEC’s shareholder meeting in 1977.)
↩︎
-
I used the
rbenchmark
library for these measurements. For example,
benchmark(write(1:10000, "/tmp/junk"))
reported that it took 1.404 seconds to execute 100 replications. The per-replication execution time was 1.404 × 1000 / 100 = 14.04 milliseconds.
↩︎
-
The benchmarked R expression was
m <- matrix(scan("/tmp/junk"), 100, 100)
. In S, the counterpart of
write()
was
read()
, but in R, it is
scan()
.
↩︎
-
MicroGnuEmacs and JOVE are still maintained today. They are packaged as
mg
and
jove
by Debian.
↩︎
-
Dave B. Johnson
explained:
For programs made with “cc” (without running “ld” explicitly), Berkeley 4.1BSD DOES (implicitly) guarantee a zero byte at address 0.
The fact that you had problems with this in porting a locally written C program from Unix 4.1 to VMS/Eunice is a bug in Eunice, not a problem with Unix.
4.1BSD crt0.o ALWAYS has a zero register save mask in it and is ALWAYS loaded at address 0 by “cc”. Crt0 is written in assembler and has an explicit “.word 0x0000” for a register save mask.
In addition, the value of the register save mask in crt0 has no affect on saving registers, since the Unix kernel does not “call” the program, but rather jumps directly into it after the register save mask. Saving the registers is not necessary since there is nowhere to return to abover crt0. In writing our Unix emulator Phoenix, I have been very careful of details like this which cause Unix programs to break. Phoenix will run almost any Unix program under VMS unmodified, even those that depend on undocumented details of the Unix environment such as this.
↩︎
-
At UKC, we have user populations of 600-700 and have totally replaced the password file by a binary file
with some integral number of bytes per user.
This means that random access can be used to access an individual entry.
Other keys to the password file (such as login name and in our case the user’s system id) are abstracted to a set of very small files which are kept in uid order - these files can be opened and searched very easily.
For compatibility purposes we generate /etc/passwd every night (with no passwords) and passwords are never printed even in their encrypted form.
↩︎
-
The modified version of sudo listed Clifford Spencer, Phil Betchel, Gretchen Phillips, John LoVerso, and Gworek himself as the authors.
↩︎




































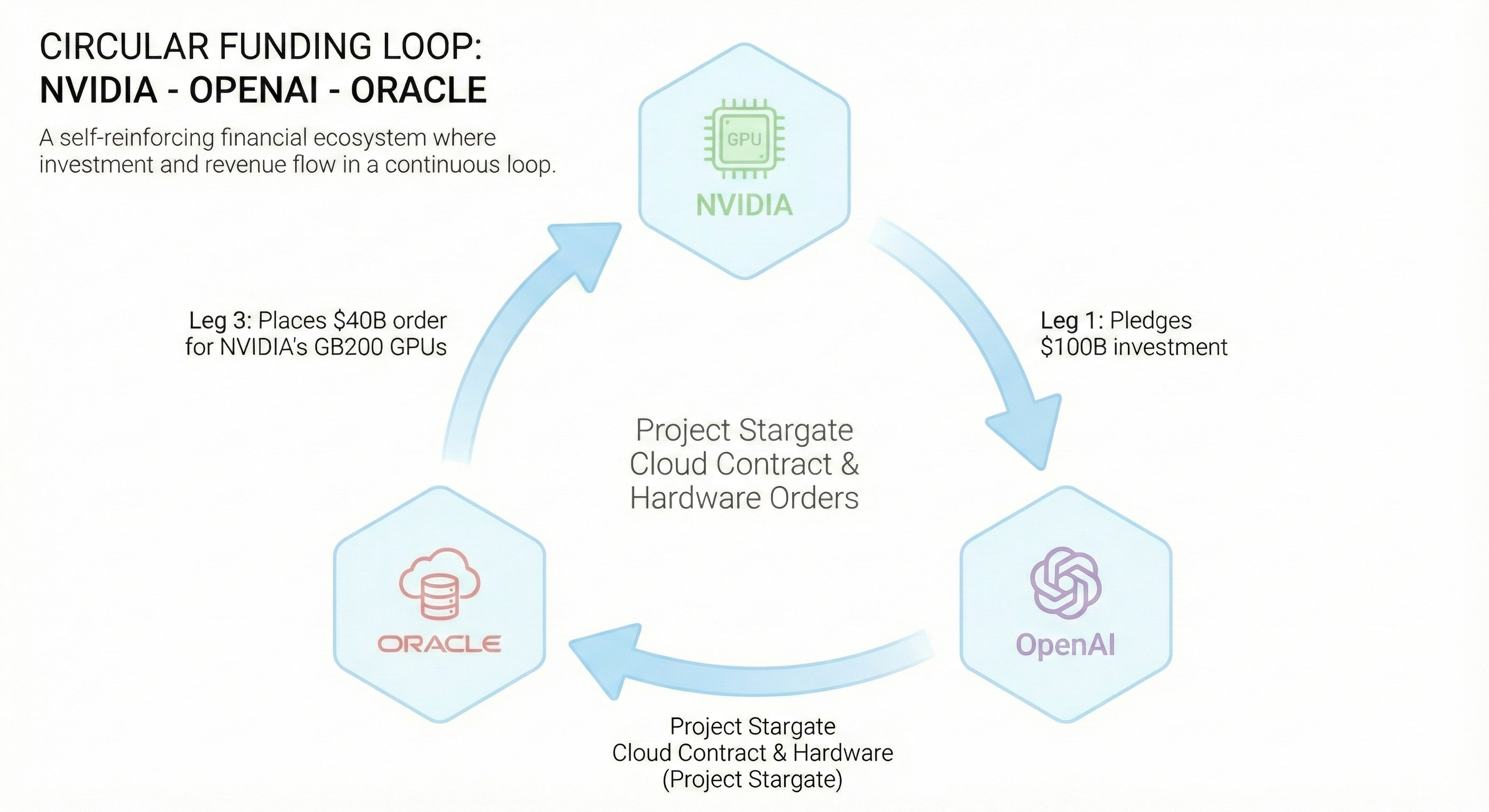
























































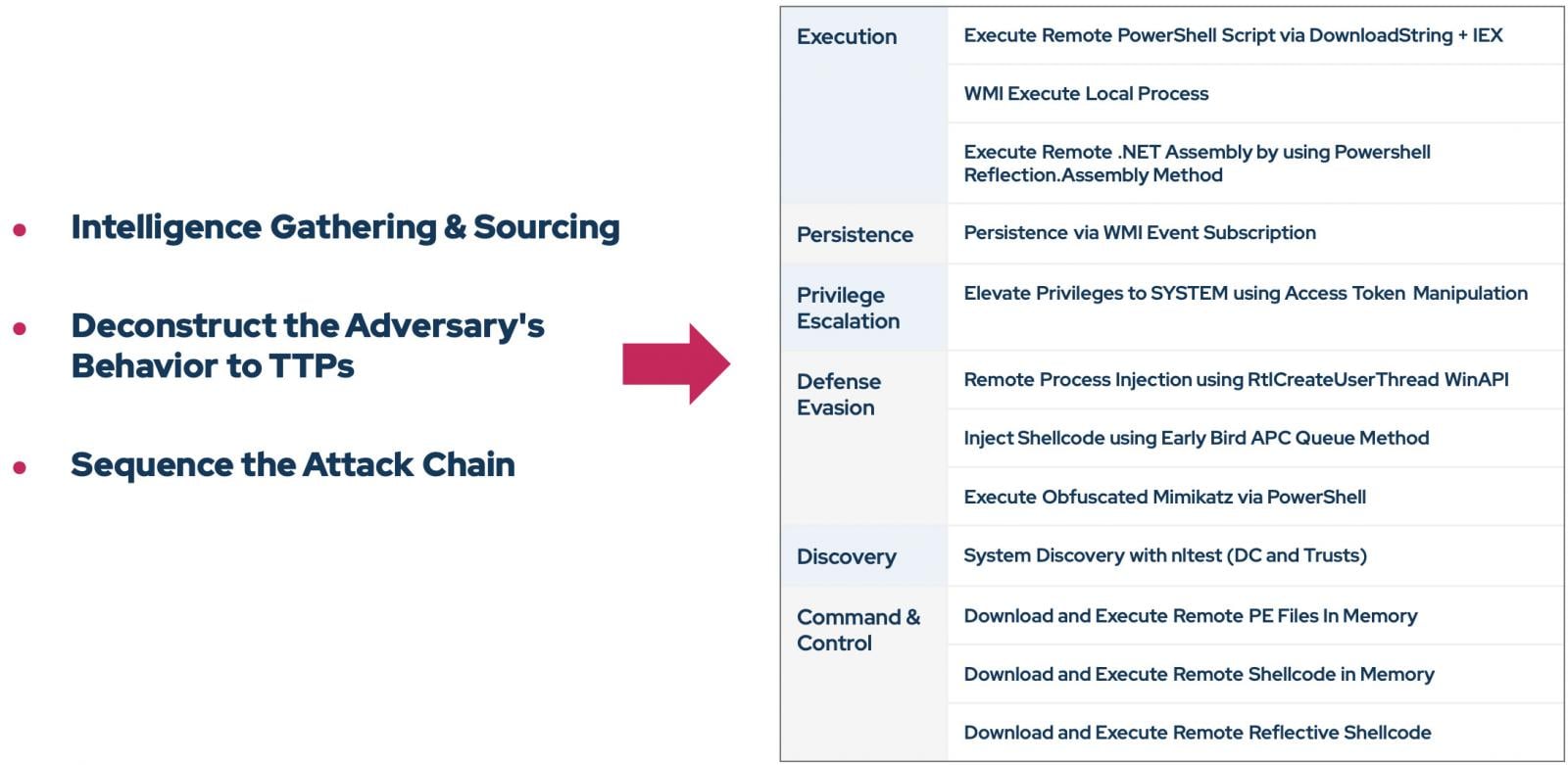














































 Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Vulnerable Tools
: A tool breaks out of the intended security boundary circumventing user interaction, leading to unexpected impact.
Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Vulnerable Tools
: A tool breaks out of the intended security boundary circumventing user interaction, leading to unexpected impact.
 Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Tools
: Non-vulnerable tools are used to perform “legitimate” actions such as reading and editing files.
AI Agent’s Settings
: Agent settings/configuration are modified using legitimate tool uses, leading to unexpected impact.
Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Tools
: Non-vulnerable tools are used to perform “legitimate” actions such as reading and editing files.
AI Agent’s Settings
: Agent settings/configuration are modified using legitimate tool uses, leading to unexpected impact.
 Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Vulnerable Tools
: A tool breaks out of the intended security boundary circumventing user interaction, leading to unexpected impact.
AI Agent’s Settings
: Agent configuration (settings) is modified using the vulnerable tool, leading to unexpected impact.
Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Vulnerable Tools
: A tool breaks out of the intended security boundary circumventing user interaction, leading to unexpected impact.
AI Agent’s Settings
: Agent configuration (settings) is modified using the vulnerable tool, leading to unexpected impact.


 Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Tools
: The agent’s tools (either vulnerable or not) are used to perform actions that trigger underlying IDE features.
Base IDE Features
: Features of the base IDE are triggered using the agent tools leading to anything from information leakage to command execution.
Prompt Injection
: Any of the the described context hijacking vectors can be used. It’s inevitable that this will eventually happen one way or the other.
Tools
: The agent’s tools (either vulnerable or not) are used to perform actions that trigger underlying IDE features.
Base IDE Features
: Features of the base IDE are triggered using the agent tools leading to anything from information leakage to command execution.


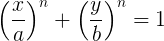

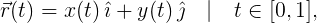

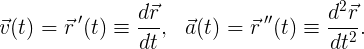

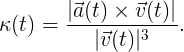































{kind=link}